Scalability
Handle an amount of work that resources can be added to the system.
Two modes
- Vertical scale
- add more computing power -> single node
- Horizontal scale
- add more machines or resources -> more nodes
Load Balancing
Target
- Minimize server response time
- Maximize throughput
Methods
- Random
- Round Robin
- Least Connection
- Least Response Time
- Least Bandwith
- Hashing
- Hash various data including connection or header information
- Custom Load
- Query the load on individual servers via SNMP
- CPU usage, memory and response time
- Combine to suit their requests
Example
DNS
DNS adopts Round Robin algorithm to return DNS Lookup response.
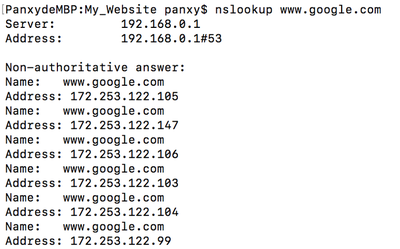
In this lookup search, we can see that multiple times search www.google.com we can get different IP addresses from DNS servers. It permutes the servers in the list one by one.
But also, load balancer for DNS attempts to re-order the list to give priority to numerically “closer” networks according to different locations.
Caching
Cache is lightning-fast, and helps record the most frequent data query, request or object. It holds every dataset in RAM and requests are handled as fast as technically possible.
The data for caching
- Cached Database Queries
- Cahced Object
Tool
-
- Advantages
- Extra database-features like persistence
- Lots of Data Types
- Both clients and servers cache the data
- AOF Log(Append Only File)
- Appending all write operations received by the server
- RDB Snapshot
- Backup file, take a full snapshot of the current Redis state
- Advantages
-
Memcached
- MultiThreaded
- Simplicity, ease of use, easy setup
Database
Partition/Sharding
- A horizontal partitioning method
- The data is partitioned accross multiple servers
- Procsessing workload against a large table can be spread
Replication
Setting up a separate copy of the data on a different node.
- Read the database logs
- Each change of the database is replicated to other copies
A replication engine can be used.
- Easy to setup
- On-going administration and management
- Additional storage for each replication
- Additional I/O and CPU usage to support the data replication process